





Abstract
Background The coronavirus disease 2019 (COVID-19) outbreak has rapidly spread around the world, causing a global public health and economic crisis. A critical limitation in detecting COVID-19-related pneumonia is that it is often manifested as a “silent pneumonia”, i.e. pulmonary auscultation that sounds “normal” using a standard stethoscope. Chest computed tomography is the gold standard for detecting COVID-19 pneumonia; however, radiation exposure, availability and cost preclude its utilisation as a screening tool for COVID-19 pneumonia. In this study we hypothesised that COVID-19 pneumonia, “silent” to the human ear using a standard stethoscope, is detectable using a full-spectrum auscultation device that contains a machine-learning analysis.
Methods Lung sound signals were acquired, using a novel full-spectrum (3–2000 Hz) stethoscope, from 164 COVID-19 pneumonia patients, 61 non-COVID-19 pneumonia patients and 141 healthy subjects. A machine-learning classifier was constructed and the data were classified into three groups: 1) normal lung sounds, 2) COVID-19 pneumonia and 3) non-COVID-19 pneumonia.
Results Standard auscultation found that 72% of the non-COVID-19 pneumonia patients had abnormal lung sounds compared with only 25% of the COVID-19 pneumonia patients. The classifier's sensitivity and specificity for the detection of COVID-19 pneumonia were 97% and 93%, respectively, when analysing the sound and infrasound data, and they were reduced to 93% and 80%, respectively, without the infrasound data (p<0.01 difference in receiver operating characteristic curves with and without infrasound).
Conclusions This study reveals that useful clinical information exists in the infrasound spectrum of COVID-19-related pneumonia and machine-learning analysis applied to the full spectrum of lung sounds is useful in its detection.
Abstract
AI applied to full-spectrum auscultation (infrasound and audible) provides superior morbidity detection in COVID-19-related pneumonia compared with standard narrow-band auscultation restricted to the audible spectrum https://bit.ly/3oTpzEN
Introduction
Severe acute respiratory syndrome due to a novel coronavirus was initially reported in China in December 2019 and is now termed coronavirus disease 2019 (COVID-19) [1]. COVID-19 may lead to severe pneumonia (COVID-19 pneumonia) requiring specialised management in the intensive care unit [2, 3]. Diagnosing pneumonia in general, and specifically due to severe acute respiratory syndrome coronavirus 2 infection, relies on clinical evaluation, including physical examination and imaging studies. However, COVID-19 pneumonia presents diagnostic challenges. Clinically, this respiratory condition has been termed “silent pneumonia” due to the paucity of pathological pulmonary auscultation findings using a standard stethoscope [4]. One possible cause for this “silence” may lie with the expertise required of the physician to diagnose auscultation findings associated with pneumonia [5, 6]. Another cause may be related to the frequency of sound waves produced in COVID-19 pneumonia, which may actually reside outside the hearing spectrum of the human ear.
Chest computed tomography (CT) has become the gold standard for diagnosing typical lung pathologies associated with COVID-19 pneumonia [7, 8]. However, in addition to the radiation exposure, availability and cost of CT scans, recent studies have shown that although chest CT sensitivity is high, its specificity is rather low [9]. Available CT data show that COVID-19 patients with both mild and severe clinical presentations demonstrate bilateral patchy infiltrations or ground-glass opacities [10, 11], for which the differential diagnosis is wide. Surprisingly, similar CT abnormalities were also observed in asymptomatic COVID-19 patients [12]. Thus, predicting the course of COVID-19 pneumonia and possible pulmonary deterioration based on CT becomes a difficult task. As a result, some patients who initially present with only mild symptoms and maintain well-preserved mechanical characteristics of the lungs with no breathing difficulties are suddenly diagnosed with severe hypoxaemia and breathing difficulties only late in the course of the disease [13, 14].
In a recent meta-analysis, overall pooled sensitivity for lung auscultation was 37% with 89% specificity [15] in identifying pneumonia-type illnesses. Due to the paucity of suspicious breath sounds, it could be that sensitivity and specificity of COVID-19 pneumonia with a regular stethoscope would be even lower. Pathophysiologically, it is possible that COVID-19 pneumonia is “silent” because of its diffuse, peripheral nature of pulmonary inflammation [3] compared with the localised consolidation of non-COVID-19 pneumonia [16].
CT and lung ultrasound are proposed as first-line screening for COVID-19 pneumonia [17]. However, during a pandemic, as the pressure to hospitalise patients increases and imaging resources become depleted, resource allocation becomes a critical issue. Patients may benefit from a medical device, based on artificial intelligence, which supports less trained medical teams (triage staff and novices) with reliable diagnostic measures and allows for specialists to attend the most difficult patients.
There have been advances in the use of the electronic stethoscope in the past decade, and new systems and adaptations are already available [18], along with new tools for analysing lung sounds by using artificial intelligence [19, 20]. Simple machine-learning methods succeeded in diagnosing COVID-19 from breath and cough sounds crudely collected on a mobile application with an area under the curve (AUC) of ∼70% [20].
As standard methods for diagnosing COVID-19 pneumonia (pulmonary auscultation and imaging) often lack specificity and sensitivity, we investigated the utility of a novel smart digital stethoscope (VoqX; Sanolla, Nesher, Israel), with which pulmonary sounds in the infrasound range (≤20 Hz) were recorded and analysed using machine-learning algorithms. This infrasound range is inaudible to the human ear yet contains vital information for the diagnosis of lung pathologies [21–23]. Therefore, the VoqX stethoscope may support the unmet need for diagnosing COVID-19 pneumonia without relying on a physician's auscultation expertise.
Methods
Subjects and study design
This study was conducted among patients admitted to selected tertiary medical centres in Israel. The study protocol adhered to the principles of the Declaration of Helsinki and was approved by the institutional ethics board (IRB) of each hospital (IRB ethics committee of: Shamir Medical Center 0136-20-ASF; Rambam Medical Center 0631-18-RMB, HaEmek Medical Center 0136-19-EMC and 0160-19-EMC; Barzilai Medical Center 0036-20-BRZ). Written informed consent was obtained from all patients. This study is registered at ClinicalTrials.gov with identifier number NCT04910191.
The following data were collected from each patient: age, gender, height, weight, smoking status and the results of lung auscultation. Diagnosis of non-COVID-19 pneumonia was confirmed by one of the following: anamnesis, physical examination, chest radiography (or CT), blood test (blood count) and oximetry <94%. Diagnosis of COVID-19 was performed according to the criteria based on the World Health Organization's recommendation [24]. Patients were excluded if they met at least one of the following criteria: <18 years of age, pregnant, had any type of chest malformation, under another's guardianship or weighed >150 kg. The healthy group was composed of healthy volunteers that accompanied patients to the hospital and did not suffer from any chronic or acute respiratory disease.
Respiratory sound data
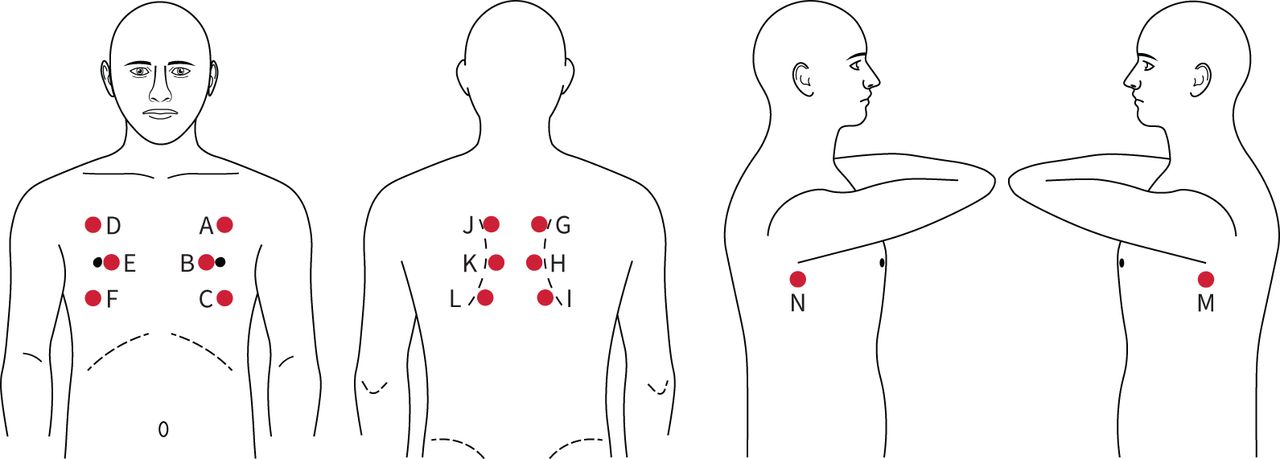
Real-time respiratory sound recordings were performed during the physical examination while the subjects were in a sitting position. The VoqX stethoscope was placed on top of the patient's clothing. Acquisition of respiratory sounds was performed over a single layer of clothing for all patients, with no need for direct skin contact. For every patient, 14 sites (A–N) were auscultated, within the anterior, posterior and lateral chest walls (figure 1). For every one of these 14 sites, 16 s were recorded. At the end of each examination, data were transferred to a hard drive and stored. In total, 1974 signals were recorded from healthy subjects (141×14 locations), 2296 from patients with COVID-19 pneumonia (164×14 locations) and 854 from patients with non-COVID-19 pneumonia (61×14 locations).
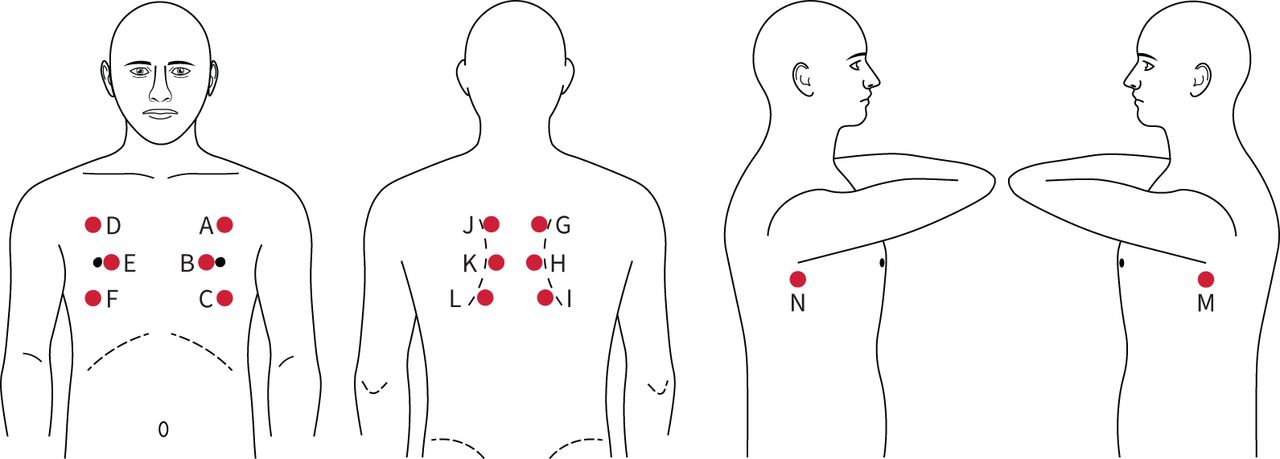
A map of the 14 sites (A–N) used for acquiring the acoustic data.
The auscultation was non-blinded for the COVID and non-COVID pneumonia patients. 1) In the COVID group, clinicians were aware patients had COVID. Despite the possible bias due to knowing the diagnosis, they reported abnormal breathing sounds in only 25% of cases. 2) In the non-COVID pneumonia group, clinicians suspected that patients had pneumonia after anamnesis and auscultation. The radiography defining the presence of pneumonia was performed afterwards. 3) In the healthy group, the auscultation was part of a different study recording healthy subjects, COPD and asthma patients. The physician auscultated to the respiratory sounds blindly and reported whether abnormal sounds were detected.
VoqX characteristics
Diagnosis by auscultation
Using the VoqX stethoscope, the examining physician was able to capture acoustic waves between 3 and 2000 Hz, as well as amplify the sound using a simple control button.
Diagnosis by visual representation
The VoqX created a graphical image of the recorded sound (a “sound signature”). The image illustrates the sound of breathing and provides an immediate visual tool for the evaluation of abnormalities.
Diagnosis by machine learning
The VoqX provides a statistical model of acoustic waves associated with various diseases. After conducting signal analysis, the device provides statistical information as to the probability of the existence (or non-existence) of several diseases. In addition, it estimates the severity of the clinical condition of the examined subject.
Connectivity
The VoqX can connect to a master device through a Bluetooth interface. Thereafter, it is possible to download and exchange data between the device and a computer for backup, analysis and patient tracking (figure 2).

Optional cloud connectivity for the VoqX. BT: Bluetooth; EMR: electronic medical record.
Signal processing and machine learning
To optimise the results of the classifier, all recorded acoustic waves were pre-processed using three stages. 1) Removing ambient noise by using a second microphone embedded in the VoqX that detected the ambient noise and dynamically reduced it from the data by an LMS (least mean square) adaptive filter. 2) Truncating each acoustic signal at the beginning and termination of the signal, to eliminate noise generated by placing and removing the stethoscope from the body surface. This was performed by a threshold on the first derivative of the signal in the first and last 1 s of the data. 3) Removing clicking noises that were generated from movements of the stethoscope on the patient's clothing during examination. This process was performed by finding spikes in the signal that were greater than 3 times the median amplitude of the signal.
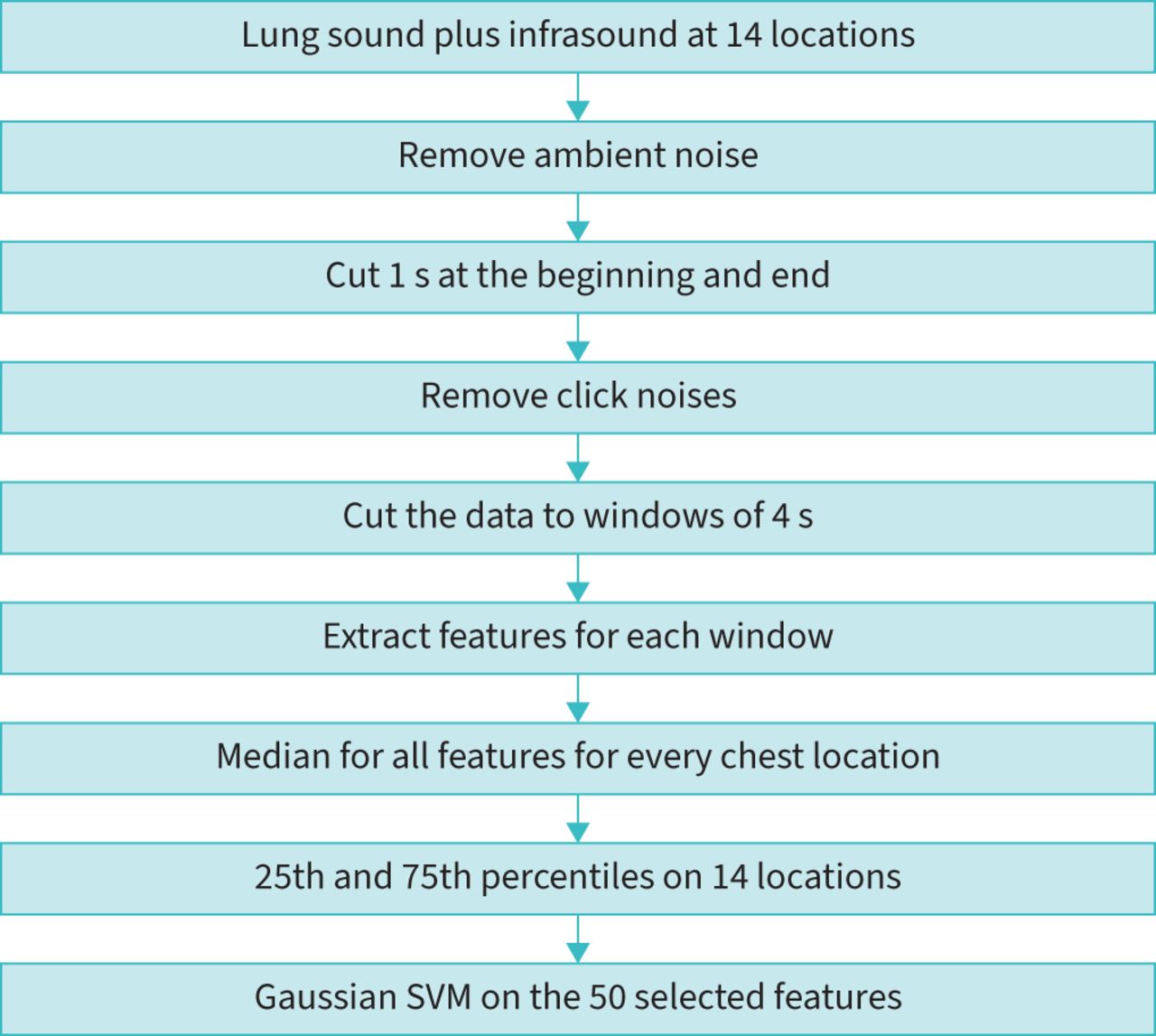
Thereafter, 164 features were calculated in the time and frequency domains (supplementary material). The features of the time domain were statistical features (e.g. average, standard deviation, median, etc.) and features related to the shape of the sound wave (e.g. skewness and kurtosis). The features of the frequency domain included the dominant frequencies at various ranges, including their magnitudes and AUCs. Moreover, in the frequency domain, we calculated Mel-Frequency Cepstrum Coefficient (MFCC) features. Heart and breathing rates were extracted from the data and added to the classifier. The algorithm is described in the flowchart in figure 3. The features were calculated for windows of 4 s and the output for every chest location was the median value. Next, the 25th and 75th percentiles of the features (14 measurements for 14 locations) were calculated and served as the final features for every patient. Finally, the final features were ranked according to their p-values for distinguishing between the three groups (supplementary material); 144 out of 164 final features had a significant p-value (p<0.05) and the best 50 were chosen. These 50 features were analysed by a Gaussian support vector machine (SVM) classifier [25] to classify normal, non-COVID-19 pneumonia and COVID-19 pneumonia. The Gaussian SVM was chosen among 32 different methods since it provided the best performance. For a new breathing sound, the classifier calculates the distance between its features and the features of all three groups, and chooses which group is the closest. The Gaussian SVM was performed with an automatic kernel scale and a box constraint of 2. The features were standardised before the analysis. Since the sample size was different for the three groups, a standard method of a cost function was applied to the error calculation to equalise the weight of every group. Moreover, in order to generate an automatic objective process of investigating the performance, the data were randomly divided 12 times to 60% of the dataset used as training signals and 40% used as a test group.
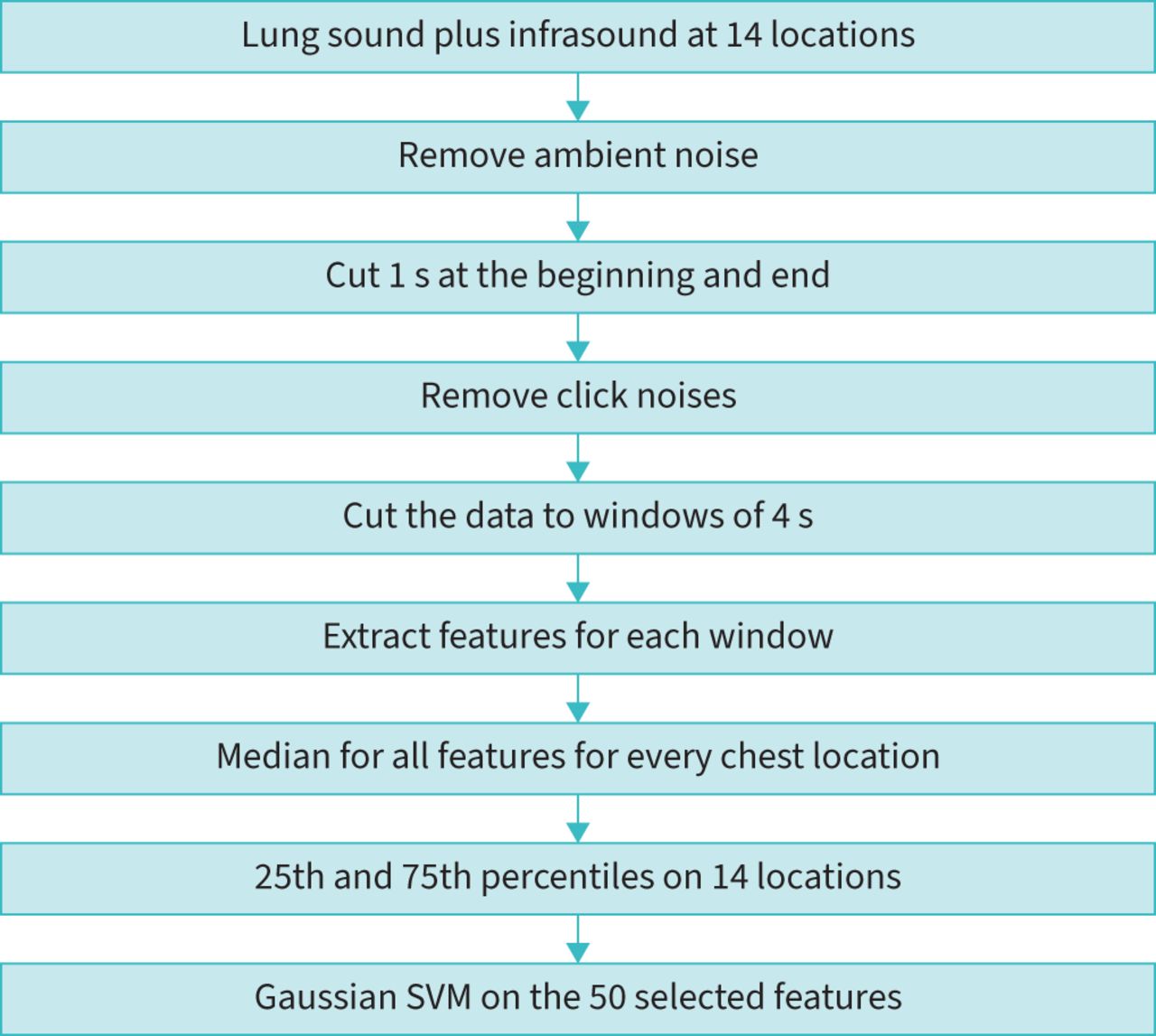
Flowchart of the pre-processing and machine-learning algorithm. SVM: support vector machine.
Statistical analysis
The p-value of the features was calculated by one-way ANOVA.
The sensitivity, specificity, accuracy, positive predictive value and negative predictive value were calculated for each run of the classifier, for the cross-validation group (during the learning process in the creation of the classifier) and for the test group that did not participate during the learning. Receiver operating characteristic (ROC) curve analysis was performed and the AUCs with and without infrasound were compared [26].
Results
61 patients with non-COVID-19 pneumonia, 164 patients with COVID-19 pneumonia and 141 healthy patients were included in the study (table 1). In 44 out of 61 patients (72%) with non-COVID-19 pneumonia, physical examination revealed an abnormality on lung auscultation: 59% had only crackles, 7% had only wheezes, 3% had both crackles and wheezes, and in 3%, the intensity of breathing sounds was perceived as reduced. In contrast, abnormalities on lung auscultation were detected in only 41 out of 164 (25%) patients with COVID-19 pneumonia: 19% had crackles, 4% had wheezes, and in 2%, breathing sounds were perceived as reduced.
Selected patient characteristics and physical findings by lung auscultation
All breathing sounds were analysed using machine-learning software. The input was 164 unique features that were calculated for every signal. Out of the 164 features, 144 were able to distinguish between the three groups by ANOVA (p<0.05); however, only 50 features were selected to reduce the calculation time, as adding more than 50 features did not improve classification performance. The 50 features were selected according to their level of performance in distinguishing between the three study groups. An example of features that improved the performance is given in figure 4. Figure 4a shows that adding infrasound data to the analyses helps to distinguish between the three groups.

Two features (out of 164) that strongly depend on infrasound: Mel-Frequency Cepstrum Coefficient 1 (MFCC1) as a function of magnitude of breathing frequency for COVID-19, normal and non-COVID-19: a) with infrasound and b) no infrasound.
Visual sound signatures created by the device are demonstrated in figure 5a–c. Figure 5a shows three dense blue columns that represent three respiratory cycles of a healthy subject. Figure 5b shows the visual sound signature of a COVID-19 patient for whom detecting the breathing cycle was difficult and higher intensities for various frequencies were found. Figure 5c represents a non-COVID-19 pneumonia patient, in which very high intensities are shown along all frequencies, due to crackles.

Visual sound signatures of the VoqX recorded from: a) a healthy subject, b) a COVID-19 pneumonia patient and c) a patient with non-COVID-19 pneumonia. The colours represent the intensity of breathing sounds (dB full scale).
60% of the signals were used to train the classifier. The other 40% served as a test group to investigate the performance of the classifier. This process was randomly performed 12 times. The results are described in table 2. Table 2 contains three kinds of results: detection in the test group that did not participate in the learning process, the cross-validation performed during the learning process to optimise the classifier and the results of auscultation by using an acoustic stethoscope. The results show that the performance of the classifier is statistically improved when adding infrasound to the analysis (p<0.01) and the sensitivity of detecting COVID-19 pneumonia reached 97% with a specificity of 93% (table 2).
Performance measures from 12 runs of random sets
In addition, we collected data from eight asymptomatic subjects who were COVID-19 positive by nasopharyngeal PCR examination (112 signals) and were living in a quarantine facility. These subjects served as a second test group to validate our ability to diagnose asymptomatic patients. The classifier classified seven of them as COVID-19 pneumonia and one was diagnosed with non-COVID-19 pneumonia. The radiographs of these patients identified three patients with COVID-19 pneumonia, while the other five (although diagnosed with the COVID-19 virus) did not show any COVID-19 findings using the radiographs.
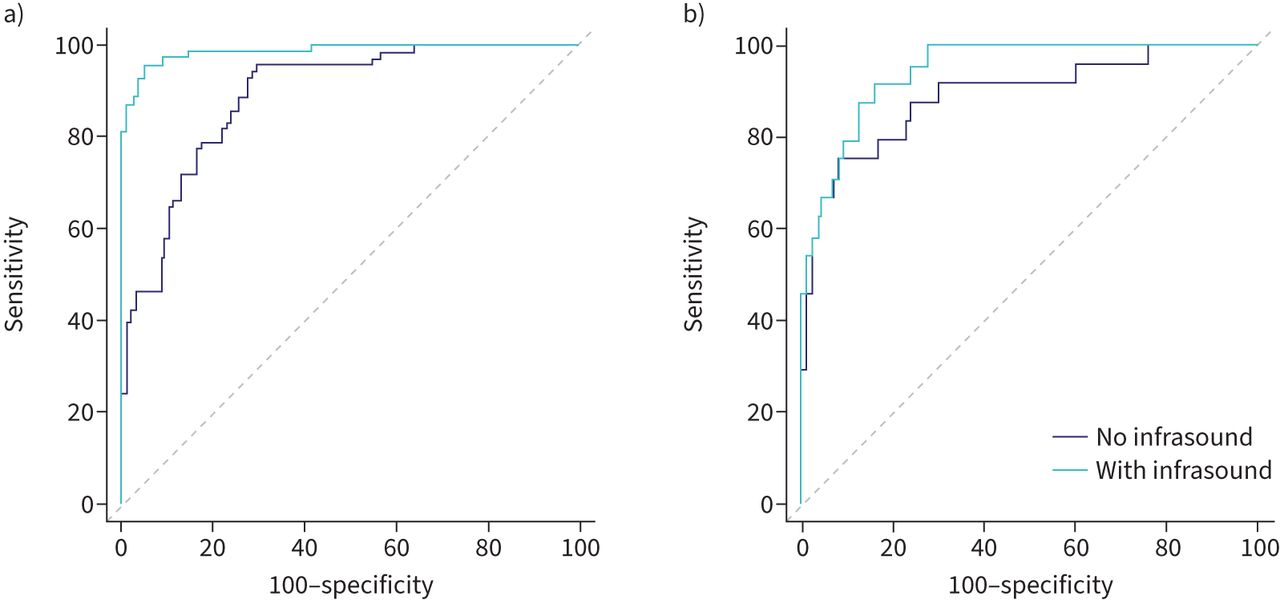
Finally, the ROC curves with and without infrasound were statistically compared and found to be significantly different for the COVID-19 pneumonia group (p<0.01; AUC 0.98 with infrasound and 0.92 without infrasound) (figure 6a), while for the patients with non-COVID-19 pneumonia, the ROC curve difference was insignificant (AUC 0.92 with infrasound and 0.90 without infrasound) (figure 6b).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Receiver operating characteristic curves after classification with and without infrasound: a) detection of “silent” COVID-19 pneumonia and b) detection of non-COVID-19 pneumonia.
Discussion
In this study, we demonstrated that the use of the novel VoqX digital stethoscope to acquire breathing signals in the sound and infrasound range of frequencies and analysing the signals with machine-learning methods can distinguish between patients with COVID-19 pneumonia, non-COVID-19 pneumonia and healthy subjects with an accuracy of 92%, while standard auscultation by an acoustic stethoscope reached an accuracy of 52% (table 2). Infrasound plays an important role in detecting “silent pneumonia” and the VoqX provides this ability (table 2). This phenomenon is further emphasised when the first MFCC is plotted versus the magnitude of breathing frequency (figure 4). The MFCC approximates the human auditory system's response at different frequency ranges. The magnitude of breathing frequency is the magnitude at the frequency domain of the peak that was generated from the breathing rate. Figure 4a shows that adding infrasound data to the analyses helps to distinguish between the three groups. Without infrasound analysis, the features of healthy subjects and patients with COVID-19 pneumonia are indistinguishable (figure 4b). Comparing classification results of breathing signals of data containing infrasound with data having limited bandwidth shows improvement of the specificity from 80% for limited bandwidth data without infrasound to 93% for the data with the full spectrum including infrasound (table 2).
To the best of our knowledge, the VoqX is the first device that utilises machine learning on the infrasound and sound of breathing to detect COVID-19 pneumonia more accurately, reaching an AUC of 94% (figure 6).
Limitations and future work
Acquiring data at 14 locations on the chest wall is time consuming (16 s for the processing for each location). Thus, a new classifier is currently being developed to diagnose lung diseases by using only four locations on the back. Acquiring the data will require 4×16=64 s and the analysis will take 30 s. Such a time frame for diagnosis enables the integration of the VoqX in in-clinic practice.
It is noted that there was a significant difference between the age of the healthy subjects and the patients. However, as far as we know, there is no need to consider the patient's age while auscultating to lung sounds [27].
Conclusions
The current study shows that by using the full range of respiratory sound waves (audible and infrasound) it is possible to diagnose COVID-19 pneumonia. We have shown that adding the infrasound data of breathing improves the accuracy of COVID-19 pneumonia detection (“silent pneumonia”). Furthermore, since COVID-19 pneumonia is significantly manifested in the infrasound, while non-COVID-19 pneumonia has most of its acoustic energy in the audible range, using the novel VoqX digital stethoscope helps distinguish between COVID-19 pneumonia and non-COVID-19 pneumonia.
Supplementary material
Supplementary Material
Please note: supplementary material is not edited by the Editorial Office, and is uploaded as it has been supplied by the author.
Features for machine learning and their p-values for separating the three groups 00152-2022.supplement
Footnotes
Provenance: Submitted article, peer reviewed.
This study is registered at ClinicalTrials.gov with identifier number NCT04910191. All data and codes are available at GitHub (https://github.com/Sanolla/Lung_Classifier).
Conflict of interest: N. Bachner-Hinenzon and D. Adler are full-time employees of Sanolla. The other authors do not have any conflict of interests.
Support statement: This study was support by the Israeli Innovation Authority of the Israeli Government. Funding information for this article has been deposited with the Crossref Funder Registry.
- Received March 28, 2022.
- Accepted July 29, 2022.
- Copyright ©The authors 2022
This version is distributed under the terms of the Creative Commons Attribution Non-Commercial Licence 4.0. For commercial reproduction rights and permissions contact permissions{at}ersnet.org
References










